人总是害怕去追求自己最重要的梦想,因为他们觉得自己不配拥有,或者觉得自己没有能力去完成。 ——保罗.柯艾略《牧羊少年奇幻之旅》
写在前面
博文内容部分参考于《Linux性能优化》中文版一书,学习后记录,感兴趣小伙伴可以支持下译者
博文涉及内容:
CPU相关的基础指标的解释:运行队列,平均负载,上下文切换,中断,CPU使用率CPU监控信息统计的常用工具中关于CPU信息的统计方式:
vmstatmpstatsartop(3.0)
人总是害怕去追求自己最重要的梦想,因为他们觉得自己不配拥有,或者觉得自己没有能力去完成。 ——保罗.柯艾略《牧羊少年奇幻之旅》
CPU相关的基础指标运行队列统计
在Linux中,一个进程有可运行的,阻塞的(正在等待一个事件的完成)两种情况。阻塞进程可能在等待的是从I/O设备来的数据,或者是系统调用的结果。
如果进程是可运行的,那就意味着它要和其他也是可运行的进程竞争CPU时间。一个可运行的进程不一定会使用CPU,但是当Linux调度器决定下一个要运行的进程时,它会从可运行进程队列中挑选。
如果进程是可运行的,同时又在等待使用处理器,这些进程就构成了运行队列。运行队列越长,处于等待状态的进程就越多
平均负载 **系统的负载是指正在运行和可运行的进程总数 **。比如,如果正在运行的进程为两个,而可运行的进程为三个,那么系统负载就是5,平均负载是给定时间内的负载量。
上下文切换 制造出给定单处理器同时运行多个任务的假象, Linux内核就要不断地在不同的进程间切换。这种不同进程间的切换称为上下文切换
上下文切换时, CPU要保存旧进程的所有上下文信息,并取出新进程的所有上下文信息。上下文中包含了Linux跟踪新进程的大量信息,其中包括: 进程正在执行的指令,分配给进程的内存,进程打开的文件等
上下文切换涉及大量信息的移动,**上下文切换的开销可以是相当大的 **。
上下文切换可以是内核调度的结果。为了保证公平地给每个进程分配处理器时间,内核周期性地中断正在运行的进程, 周期性中断或定时发生时,系统都可能进行上下文切换。每秒定时中断的次数与架构和内核版本有关。
一个检查中断频率的简单方法是用/proc/interrupts文件,它可以确定已知时长内发生的中断次数。
1 2 3 4 5 6 7 8 ┌──[root@vms81.liruilongs.github.io]-[~] └─$cat /proc/interrupts | grep time; sleep 5 ;cat /proc/interrupts | grep time 0: 337 0 IO-APIC-edge timer LOC: 9896498 9871317 Local timer interrupts 0: 337 0 IO-APIC-edge timer LOC: 9901529 9876213 Local timer interrupts ┌──[root@vms81.liruilongs.github.io]-[~] └─$
上面定时器的启动频率为(9896498-9901529)/5 =1000,即每秒要终端1000次,同时也可以理解为内核为sleep进程分配了1000次CPU,
如果你的上下文切换明显多于定时器中断,那么这些切换极有可能是由I/O请求或其他长时间运行的系统调用(如休眠)造成的。当应用请求的操作不能立即完成时,内核启动该操作,保存请求进程,并尝试切换到另一个已就绪进程。这能让处理器尽量保持忙状态。
中断 处理器还周期性地从硬件设备接收中断。当设备有事件需要内核处理时,它通常就会触发这些中断。
比如,如果磁盘控制器刚刚完成从驱动器取数据块的操作,并准备好提供给内核,那么磁盘控制器就会触发一个中断。对内核收到的每个中断,如果已经有相应的已注册的中断处理程序,就运行该程序,否则将忽略这个中断。
**中断处理程序在系统中具有很高的运行优先级,并且通常执行速度也很快 **。查看/proc/interrupts文件可以显示出哪些CPU上触发了哪些中断。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 ┌──[root@vms81.liruilongs.github.io]-[~] └─$cat /proc/interrupts CPU0 CPU1 0: 337 0 IO-APIC-edge timer 1: 10 0 IO-APIC-edge i8042 8: 1 0 IO-APIC-edge rtc0 9: 0 0 IO-APIC-fasteoi acpi 12: 16 0 IO-APIC-edge i8042 14: 0 0 IO-APIC-edge ata_piix 15: 0 0 IO-APIC-edge ata_piix 17: 57939 0 IO-APIC-fasteoi ioc0 18: 14 9800 IO-APIC-fasteoi ens32 24: 0 0 PCI-MSI-edge PCIe PME, pciehp 25: 0 0 PCI-MSI-edge PCIe PME, pciehp 26: 0 0 PCI-MSI-edge PCIe PME, pciehp 27: 0 0 PCI-MSI-edge PCIe PME, pciehp ....................... THR: 0 0 Threshold APIC interrupts DFR: 0 0 Deferred Error APIC interrupts MCE: 0 0 Machine check exceptions MCP: 37 37 Machine check polls ERR: 0 MIS: 0 PIN: 0 0 Posted-interrupt notification event PIW: 0 0 Posted-interrupt wakeup event ┌──[root@vms81.liruilongs.github.io]-[~] └─$
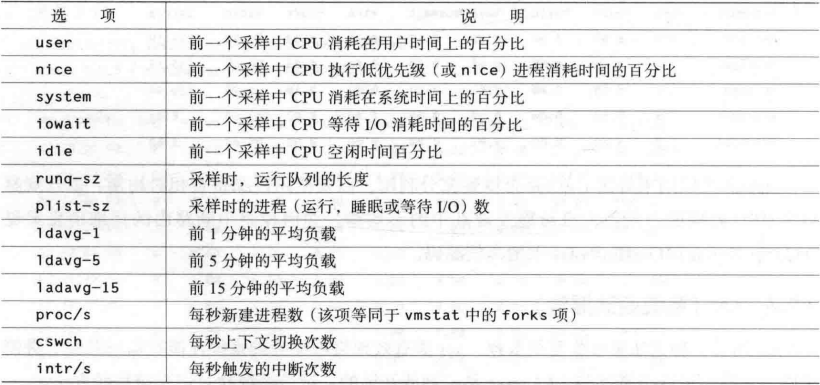
CPU使用率
在任何给定的时间, CPU可以执行以下七件事情中的一个
CPU可以是空闲的,这意味着处理器实际上没有做任何工作,并且等待有任务可以执行。
CPU可以运行用户代码,即指定的“用户”时间。
CPU可以执行Linux内核中的应用程序代码,这就是“系统”时间。
CPU可以执行“比较友好”的或者优先级被设置为低于一般进程的用户代码。
CPU可以处于iowait状态,即系统正在等待10 (如磁盘或网络)完成。
CPU可以处于irq状态,即它正在用高优先级代码处理硬件中断。
CPU可以处于softirq模式,即系统正在执行同样由中断触发的内核代码,只不过其运行于较低优先级(下半部代码)
一个具有 高“系统”百分比 高“用户”时间
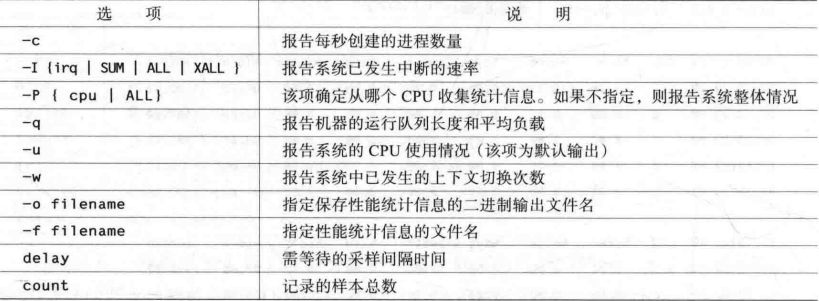
CPU监控信息统计 vmstat (虚拟内存统计) vmstat是一个很有用的命令,它能获取整个系统性能的粗略信息,包括:
正在运行的进程个数 CPU的使用情况 CPU接收的中断个数 调度器执行的上下文切换次数
语法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 ┌──(liruilong㉿Liruilong)-[/mnt/c/Users/lenovo] └─$ vmstat -help Usage: vmstat [options] [delay [count]] Options: -a, --active active/inactive memory -f, --forks number of forks since boot -m, --slabs slabinfo -n, --one-header do not redisplay header -s, --stats event counter statistics -d, --disk disk statistics -D, --disk-sum summarize disk statistics -p, --partition <dev> partition specific statistics -S, --unit <char> define display unit -w, --wide wide output -t, --timestamp show timestamp -h, --help display this help and exit -V, --version output version information and exit For more details see vmstat(8). ┌──(liruilong㉿Liruilong)-[/mnt/c/Users/lenovo] └─$
CPU性能相关的选项 1 $vmstat [-n] [-s] [delay [count ]]
vmstat运行于两种模式:采样模式和平均模式。如果不指定参数,则vmstat统计运行于平均模式下.
vmstat显示从系统启动以来所有统计数据的均值。但是,如果指定了延迟,那么第一个采样仍然是系统启动以来的均值,但之后vmstat按延迟秒数采样系统并显示统计数据。
参数
-n 参数的区别
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ┌──[root@vms81.liruilongs.github.io]-[~] └─$vmstat 1 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 0 1064772 2072 1764796 0 0 60 26 1501 832 8 4 87 1 0 0 0 0 1064964 2072 1764800 0 0 0 70 2993 4939 19 8 73 0 0 0 0 0 1064400 2072 1764800 0 0 0 0 2832 6916 24 10 66 0 0 .............. 0 0 0 1064156 2072 1764952 0 0 0 32 2449 3900 3 2 95 0 0 0 0 0 1064196 2072 1764860 0 0 0 16 2647 4124 6 2 91 0 0 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 4 0 0 1058828 2072 1764860 0 0 0 24 3121 5182 8 4 88 0 0 1 0 0 1064608 2072 1764820 0 0 0 0 3070 5297 10 6 83 0 0 0 0 0 1064608 2072 1764820 0 0 0 32 2674 4136 3 2 95 0 0 0 0 0 1064296 2072 1764820 0 0 0 0 2560 3943 3 1 95 0 0 ^C
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 ┌──[root@vms81.liruilongs.github.io]-[~] └─$vmstat -n 1 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 1063952 2072 1764808 0 0 59 26 1501 838 8 4 87 1 0 7 0 0 1064472 2072 1764812 0 0 0 38 2869 4611 9 4 87 0 0 2 0 0 1063476 2072 1764876 0 0 0 28 3467 8176 31 15 54 0 0 0 0 0 1063476 2072 1764876 0 0 0 0 2482 3629 14 2 84 0 0 0 0 0 1063476 2072 1764876 0 0 0 28 2459 3691 3 2 96 0 0 0 0 0 1063368 2072 1764864 0 0 0 36 2691 4061 5 1 94 0 0 0 0 0 1062864 2072 1764864 0 0 0 44 2714 4420 6 2 92 0 0 0 0 0 1063104 2072 1764864 0 0 0 32 2963 4514 8 3 88 0 0 ............ 1 0 0 1063868 2072 1765000 0 0 0 107 2657 6989 33 14 52 0 0 0 0 0 1063868 2072 1765000 0 0 0 0 2830 4315 6 3 91 0 0 0 0 0 1063868 2072 1765000 0 0 0 28 2430 3908 5 3 92 0 0 0 0 0 1063868 2072 1765000 0 0 0 0 2358 3551 2 2 96 0 0 ......... 1 0 0 1064136 2072 1765112 0 0 0 0 2736 4000 6 3 91 0 0 4 0 0 1063764 2072 1765112 0 0 0 48 2492 3779 5 2 93 1 0 0 0 0 1063484 2072 1765112 0 0 0 0 2650 4071 4 2 94 0 0 0 0 0 1063304 2072 1765116 0 0 0 99 2727 4430 7 3 90 0 0 0 0 0 1063392 2072 1765116 0 0 0 12 2554 3811 2 1 97 0 0 0 0 0 1064012 2072 1765120 0 0 0 48 2585 4291 14 5 81 0 0 0 0 0 1064136 2072 1765120 0 0 0 0 2576 4057 4 2 94 0 0 ^C ┌──[root@vms81.liruilongs.github.io]-[~] └─$
-s 的统计
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 ┌──[root@vms81.liruilongs.github.io]-[~] └─$vmstat -s 4030172 K total memory 1199020 K used memory 1277200 K active memory 1428408 K inactive memory 1064028 K free memory 2072 K buffer memory 1765052 K swap cache 0 K total swap 0 K used swap 0 K free swap 206387 non-nice user cpu ticks 3 nice user cpu ticks 100381 system cpu ticks 2184710 idle cpu ticks 12604 IO-wait cpu ticks 0 IRQ cpu ticks 4699 softirq cpu ticks 0 stolen cpu ticks 1473622 pages paged in 652550 pages paged out 0 pages swapped in 0 pages swapped out 37633050 interrupts 64361523 CPU context switches 1642162657 boot time 210962 forks ┌──[root@vms81.liruilongs.github.io]-[~] └─$
CPU相关的列名含义
CPU相关的列名含义
vmstat的开销很低,可以让它在控制台上或窗口中持续运行,甚至是在负载非常重的服务器上是很实用的。
1 2 3 4 5 6 7 ┌──[root@vms81.liruilongs.github.io]-[~] └─$vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 0 1057540 2072 1761012 0 0 68 27 1501 595 8 4 87 1 0 ┌──[root@vms81.liruilongs.github.io]-[~] └─$
查看CPU平均值,当前系统中,可运行进程为2(r),被阻塞的进程为0(b),系统发生中断次数1501(in),系统发生上下文切换次数为595(cs),系统代码消耗CPU为4%(sy),用户代码消耗CPU为8%(us),系统空闲占比87%(id),剩余1%属于等待IO消耗的CPU空闲状态(wa),
上下文切换的数量小于中断的数量。调度器切换进程的次数少于定时器中断触发的次数 在定时器中断触发的大多数时候,调度器没有任何工作要做,因此它也不需要从空闲进程切换出去。
CPU 统计的含义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ┌──[root@vms81.liruilongs.github.io]-[~] └─$vmstat -s .......... 206387 non-nice user cpu ticks 3 nice user cpu ticks 100381 system cpu ticks 2184710 idle cpu ticks 12604 IO-wait cpu ticks 0 IRQ cpu ticks 4699 softirq cpu ticks 0 stolen cpu ticks ............ 37633050 interrupts 64361523 CPU context switches ........... 210962 forks
这里的ticks为一个时间单位,相关数据为自系统启动时间以来的数据。forks表示系统创建以来的进程数,CPU context switches表示上下文文切换次数,interrupts即中断次数,剩下的参数对应上面的列理解即可,stolen cpu 这个不太理解
top(3.0.X 版本) top 小伙伴应该不陌生,不多讲,直接看语法
语法 1 2 3 4 5 6 7 ┌──[root@vms81.liruilongs.github.io]-[~] └─$top -help procps-ng version 3.3.10 Usage: top -hv | -bcHiOSs -d secs -n max -u|U user -p pid(s) -o field -w [cols] ┌──[root@vms81.liruilongs.github.io]-[~] └─$
top呈现为一个降序列表,排在最前面的是最占用CPU的进程。
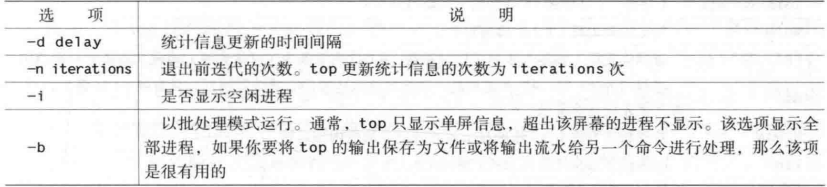
CPU性能相关的选项 1 $top [-d delay] [-n iter] [-i] [-b]
top实际有两种模式的选项:命令行选项和运行时选项。
命令行选项
命令行选项决定top如何显示其信息。
命令行选项
下面问间隔3s统计2次的top信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 ┌──[root@vms81.liruilongs.github.io]-[~] └─$top -d 3 -n 2 top - 09:26:22 up 13:08, 1 user, load average: 0.56, 0.48, 0.55 Tasks: 215 total, 1 running, 214 sleeping, 0 stopped, 0 zombie %Cpu(s): 9.9 us, 5.5 sy, 0.0 ni, 84.3 id, 0.2 wa, 0.0 hi, 0.2 si, 0.0 st KiB Mem : 4030172 total, 1079708 free, 1204872 used, 1745592 buff/cache KiB Swap: 0 total, 0 free, 0 used. 2470484 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 2195 root 20 0 1174904 380988 47392 S 10.0 9.5 95:15.71 kube-apiserver 963 root 20 0 1777988 142376 59968 S 5.6 3.5 41:04.34 kubelet 2204 root 20 0 823728 98312 36136 S 5.6 2.4 47:06.26 kube-controller 4348 root 20 0 1657820 47488 21052 S 5.3 1.2 42:28.29 calico-node 2266 root 20 0 10.696g 77632 19904 S 3.0 1.9 23:51.16 etcd 1121 root 20 0 1369820 85076 28388 S 2.7 2.1 15:55.04 dockerd 973 root 20 0 1099192 43512 16860 S 0.7 1.1 4:32.81 containerd 3057 root 20 0 737756 29904 12424 S 0.7 0.7 3:34.82 speaker 3564 root 20 0 713096 15152 4312 S 0.7 0.4 1:50.31 containerd-shim 4313 root 20 0 713096 15596 4256 S 0.7 0.4 1:25.70 containerd-shim 9 root 20 0 0 0 0 S 0.3 0.0 2:05.06 rcu_sched 13 root 20 0 0 0 0 S 0.3 0.0 0:07.26 ksoftirqd/1 2214 root 20 0 754268 41856 19352 S 0.3 1.0 4:25.88 kube-scheduler 3774 root 20 0 751232 34032 15932 S 0.3 0.8 1:25.77 coredns 4261 root 20 0 751488 30832 15880 S 0.3 0.8 1:30.06 coredns 4369 polkitd 20 0 745532 33232 14124 S 0.3 0.8 0:21.00 kube-controller 1 root 20 0 191024 4028 2516 S 0.0 0.1 0:47.38 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.05 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:07.85 ksoftirqd/0 4 root 20 0 0 0 0 S 0.0 0.0 0:06.99 kworker/0:0 .......
下面为只显示非空闲进程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 ┌──[root@vms81.liruilongs.github.io]-[~] └─$top -i top - 09:35:45 up 13:18, 1 user, load average: 0.17, 0.45, 0.53 Tasks: 216 total, 3 running, 213 sleeping, 0 stopped, 0 zombie %Cpu(s): 7.4 us, 3.2 sy, 0.0 ni, 89.1 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 st KiB Mem : 4030172 total, 1070632 free, 1213464 used, 1746076 buff/cache KiB Swap: 0 total, 0 free, 0 used. 2461980 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 2195 root 20 0 1174904 380988 47392 S 14.3 9.5 96:25.19 kube-apiserver 2204 root 20 0 823728 98312 36136 S 6.3 2.4 47:40.78 kube-controller 4348 root 20 0 1657820 47516 21052 S 5.3 1.2 42:59.36 calico-node 963 root 20 0 1777988 141712 59968 S 4.3 3.5 41:34.55 kubelet 2266 root 20 0 10.696g 78684 19904 S 3.3 2.0 24:08.17 etcd 40370 root 20 0 745236 17168 8388 R 2.3 0.4 0:00.07 calico 1121 root 20 0 1369820 85496 28388 S 1.7 2.1 16:06.78 dockerd 2214 root 20 0 754268 41856 19352 S 0.7 1.0 4:28.98 kube-scheduler 3057 root 20 0 737756 30136 12424 S 0.7 0.7 3:37.40 speaker 9 root 20 0 0 0 0 S 0.3 0.0 2:06.53 rcu_sched 3023 root 20 0 713096 12892 3636 S 0.3 0.3 0:05.56 containerd-shim ┌──[root@vms81.liruilongs.github.io]-[~] └─$
-b 显示全部的进程,默认只显示当前的页能容纳的进程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 ┌──[root@vms81.liruilongs.github.io]-[~] └─$top -d 3 -n 1 -b top - 09:31:42 up 13:14, 1 user, load average: 1.21, 0.70, 0.61 Tasks: 215 total, 1 running, 214 sleeping, 0 stopped, 0 zombie %Cpu(s): 3.6 us, 3.6 sy, 0.0 ni, 92.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 4030172 total, 1078040 free, 1206028 used, 1746104 buff/cache KiB Swap: 0 total, 0 free, 0 used. 2469136 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 963 root 20 0 1777988 141592 59968 S 12.5 3.5 41:21.46 kubelet 36906 root 20 0 157716 2124 1496 R 12.5 0.1 0:00.02 top 2195 root 20 0 1174904 380988 47392 S 6.2 9.5 95:55.13 kube-apiserver 2266 root 20 0 10.696g 78684 19904 S 6.2 2.0 24:00.85 etcd 3057 root 20 0 737756 30460 12424 S 6.2 0.8 3:36.32 speaker 4348 root 20 0 1657820 47304 21052 S 6.2 1.2 42:45.70 calico-node 1 root 20 0 191024 4028 2516 S 0.0 0.1 0:47.68 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.05 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:07.90 ksoftirqd/0 4 root 20 0 0 0 0 S 0.0 0.0 0:07.03 kworker/0:0 ........ 31 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kswapd0 32 root 25 5 0 0 0 S 0.0 0.0 0:00.00 ksmd 33 root 39 19 0 0 0 S 0.0 0.0 0:01.02 khugepaged 34 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 crypto 42 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kthrotld 44 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kmpath_rdacd 45 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kpsmoused 46 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kworker/0:2 ........ 259 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 scsi_tmf_4 260 root 20 0 0 0 0 S 0.0 0.0 0:00.00 scsi_eh_6 261 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 scsi_tmf_6 262 root 20 0 0 0 0 S 0.0 0.0 0:00.00 scsi_eh_7 ......... 273 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 scsi_tmf_12 274 root 20 0 0 0 0 S 0.0 0.0 0:00.00 scsi_eh_13 275 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 scsi_tmf_13 276 root 20 0 0 0 0 S 0.0 0.0 0:00.00 scsi_eh_14 277 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 scsi_tmf_14 278 root 20 0 0 0 0 S 0.0 0.0 0:00.00 scsi_eh_15 279 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 scsi_tmf_15 ........... 4297 root 20 0 4228 400 328 S 0.0 0.0 0:00.00 runsv 4313 root 20 0 713096 15340 4256 S 0.0 0.4 1:26.26 containerd-shim 4344 root 20 0 1141184 35748 16600 S 0.0 0.9 0:08.70 calico-node 4345 root 20 0 1583576 39300 18152 S 0.0 1.0 0:08.09 calico-node 4346 root 20 0 1141184 36808 17568 S 0.0 0.9 0:11.15 calico-node 4369 polkitd 20 0 745532 33232 14124 S 0.0 0.8 0:21.13 kube-controller 4526 root 20 0 756 260 196 S 0.0 0.0 0:24.63 bird6 4534 root 20 0 772 520 340 S 0.0 0.0 0:24.92 bird 14142 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kworker/u256:1 21599 root 20 0 0 0 0 S 0.0 0.0 0:00.21 kworker/1:1 26382 root 20 0 0 0 0 S 0.0 0.0 0:00.49 kworker/1:0 35491 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kworker/1:2 77429 root 20 0 148316 5532 4232 S 0.0 0.1 0:00.50 sshd 77553 root 20 0 120900 7556 1704 S 0.0 0.2 0:00.18 bash 83235 root 20 0 0 0 0 S 0.0 0.0 0:01.76 kworker/u256:0 87183 postfix 20 0 89648 4024 3012 S 0.0 0.1 0:00.01 pickup ┌──[root@vms81.liruilongs.github.io]-[~] └─$
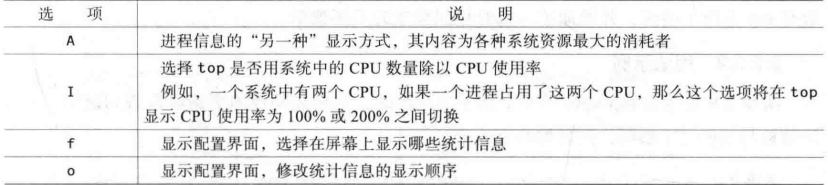
运行时top选项
运行时top
输入 A 后,显示为各个系统资源的最大消耗者,这个看不太懂,以后再研究
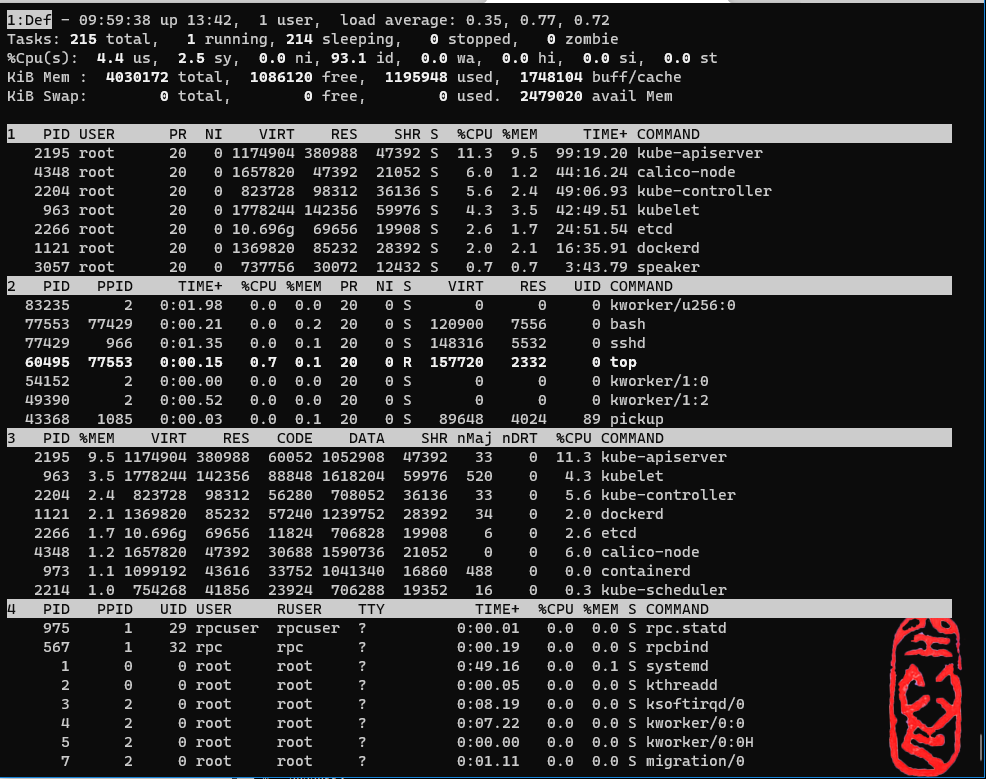
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 ┌──[root@vms81.liruilongs.github.io]-[~] └─$top -i 1:Def - 09:40:01 up 13:22, 1 user, load average: 0.17, 0.35, 0.47 Tasks: 215 total, 1 running, 214 sleeping, 0 stopped, 0 zombie %Cpu(s): 11.6 us, 6.6 sy, 0.0 ni, 81.6 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 st KiB Mem : 4030172 total, 1076864 free, 1206808 used, 1746500 buff/cache KiB Swap: 0 total, 0 free, 0 used. 2468492 avail Mem 1 PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 2204 root 20 0 823728 98312 36136 S 6.3 2.4 47:55.47 kube-controller 4348 root 20 0 1657820 47444 21052 S 5.3 1.2 43:12.72 calico-node 1121 root 20 0 1369820 85496 28388 S 2.6 2.1 16:11.81 dockerd 2266 root 20 0 10.696g 78948 19904 S 2.6 2.0 24:15.45 etcd 973 root 20 0 1099192 43784 16860 S 1.0 1.1 4:37.63 containerd 2214 root 20 0 754268 41856 19352 S 0.7 1.0 4:30.34 kube-scheduler 1 root 20 0 191024 4028 2516 S 0.3 0.1 0:48.12 systemd 2 PID PPID TIME+ %CPU %MEM PR NI S VIRT RES UID COMMAND 83235 2 0:01.82 0.0 0.0 20 0 S 0 0 0 kworker/u256:0 77553 77429 0:00.20 0.0 0.2 20 0 S 120900 7556 0 bash 77429 966 0:00.71 0.0 0.1 20 0 S 148316 5532 0 sshd 43368 1085 0:00.02 0.0 0.1 20 0 S 89648 4024 89 pickup 40247 2 0:00.17 0.3 0.0 20 0 S 0 0 0 kworker/1:1 40239 77553 0:01.26 0.3 0.1 20 0 R 157720 2332 0 top 35491 2 0:00.00 0.0 0.0 20 0 S 0 0 0 kworker/1:2 3 PID %MEM VIRT RES CODE DATA SHR nMaj nDRT %CPU COMMAND 2195 9.5 1174904 380988 60052 1052908 47392 33 0 8.9 kube-apiserver 963 3.5 1778244 141228 88848 1618204 59968 520 0 7.0 kubelet 2204 2.4 823728 98312 56280 708052 36136 33 0 6.3 kube-controller 1121 2.1 1369820 85496 57240 1239752 28388 34 0 2.6 dockerd 2266 2.0 10.696g 78948 11824 706828 19904 6 0 2.6 etcd 4348 1.2 1657820 47444 30688 1590736 21052 0 0 5.3 calico-node 973 1.1 1099192 43784 33752 1041340 16860 488 0 1.0 containerd 2214 1.0 754268 41856 23924 706288 19352 16 0 0.7 kube-scheduler 4 PID PPID UID USER RUSER TTY TIME+ %CPU %MEM S COMMAND 975 1 29 rpcuser rpcuser ? 0:00.01 0.0 0.0 S rpc.statd 567 1 32 rpc rpc ? 0:00.19 0.0 0.0 S rpcbind 1 0 0 root root ? 0:48.12 0.3 0.1 S systemd 2 0 0 root root ? 0:00.05 0.0 0.0 S kthreadd 3 2 0 root root ? 0:07.97 0.0 0.0 S ksoftirqd/0 4 2 0 root root ? 0:07.09 0.0 0.0 S kworker/0:0 5 2 0 root root ? 0:00.00 0.0 0.0 S kworker/0:0H 7 2 0 root root ? 0:01.09 0.0 0.0 S migration/0
输入F时进入配置界面,通过界面显示可以配置详细信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 ┌──[root@vms81.liruilongs.github.io]-[~] └─$top -i top - 09:48:03 up 13:30, 1 user, load average: 0.85, 0.64, 0.57 Tasks: 215 total, 1 running, 214 sleeping, 0 stopped, 0 zombie %Cpu(s): 3.4 us, 3.4 sy, 0.0 ni, 93.1 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 4030172 total, 1076900 free, 1206184 used, 1747088 buff/cache KiB Swap: 0 total, 0 free, 0 used. 2469016 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 2204 root 20 0 823728 98312 36136 S 12.5 2.4 48:24.22 kube-controller 963 root 20 0 1778244 142228 59968 S 6.2 3.5 42:12.13 kubelet 2266 root 20 0 10.696g 79468 19904 S 6.2 2.0 24:29.30 etcd 4348 root 20 0 1657820 47396 21052 S 6.2 1.2 43:37.87 calico-node 50999 root 20 0 157720 2200 1500 R 6.2 0.1 0:00.01 top Fields Management for window 1:Def, whose current sort field is %CPU Navigate with Up/Dn, Right selects for move then <Enter> or Left commits, 'd' or <Space> toggles display, 's' sets sort. Use 'q' or <Esc> to end! * PID = Process Id SUPGIDS = Supp Groups IDs * USER = Effective User Name SUPGRPS = Supp Groups Names * PR = Priority TGID = Thread Group Id * NI = Nice Value ENVIRON = Environment vars * VIRT = Virtual Image (KiB) vMj = Major Faults delta * RES = Resident Size (KiB) vMn = Minor Faults delta * SHR = Shared Memory (KiB) USED = Res+Swap Size (KiB) * S = Process Status nsIPC = IPC namespace Inode * %CPU = CPU Usage nsMNT = MNT namespace Inode * %MEM = Memory Usage (RES) nsNET = NET namespace Inode * TIME+ = CPU Time, hundredths nsPID = PID namespace Inode * COMMAND = Command Name/Line nsUSER = USER namespace Inode PPID = Parent Process pid nsUTS = UTS namespace Inode UID = Effective User Id RUID = Real User Id RUSER = Real User Name SUID = Saved User Id SUSER = Saved User Name GID = Group Id GROUP = Group Name PGRP = Process Group Id TTY = Controlling Tty TPGID = Tty Process Grp Id SID = Session Id nTH = Number of Threads P = Last Used Cpu (SMP) TIME = CPU Time SWAP = Swapped Size (KiB) CODE = Code Size (KiB) DATA = Data+Stack (KiB) nMaj = Major Page Faults nMin = Minor Page Faults nDRT = Dirty Pages Count WCHAN = Sleeping in Function Flags = Task Flags <sched.h> CGROUPS = Control Groups
**在配置统计信息时,所有当前被选择的字段将会以大写形式显示在Current Field. Order行,并在其名称旁出现一个星号(*),使用d来选择删除,使用s保存,q退出 **。
修改只留5个列名展示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 Fields Management for window 1:Def, whose current sort field is %CPU Navigate with Up/Dn, Right selects for move then <Enter> or Left commits, 'd' or <Space> toggles display, 's' sets sort. Use 'q' or <Esc> to end! * PID = Process Id SUPGIDS = Supp Groups IDs * USER = Effective User Name SUPGRPS = Supp Groups Names PR = Priority TGID = Thread Group Id NI = Nice Value ENVIRON = Environment vars VIRT = Virtual Image (KiB) vMj = Major Faults delta RES = Resident Size (KiB) vMn = Minor Faults delta SHR = Shared Memory (KiB) USED = Res+Swap Size (KiB) S = Process Status nsIPC = IPC namespace Inode * %CPU = CPU Usage nsMNT = MNT namespace Inode * %MEM = Memory Usage (RES) nsNET = NET namespace Inode TIME+ = CPU Time, hundredths nsPID = PID namespace Inode * COMMAND = Command Name/Line nsUSER = USER namespace Inode PPID = Parent Process pid nsUTS = UTS namespace Inode UID = Effective User Id RUID = Real User Id RUSER = Real User Name SUID = Saved User Id SUSER = Saved User Name GID = Group Id GROUP = Group Name PGRP = Process Group Id TTY = Controlling Tty .....
返回后发现只显示了5列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 top - 09:55:38 up 13:38, 1 user, load average: 2.16, 1.20, 0.80 Tasks: 215 total, 2 running, 213 sleeping, 0 stopped, 0 zombie %Cpu(s): 8.1 us, 4.7 sy, 0.0 ni, 87.0 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 st KiB Mem : 4030172 total, 1085120 free, 1197260 used, 1747792 buff/cache KiB Swap: 0 total, 0 free, 0 used. 2477772 avail Mem PID USER %CPU %MEM COMMAND 2195 root 14.3 9.5 kube-apiserver 2266 root 8.0 1.7 etcd 2204 root 6.0 2.4 kube-controller 4348 root 5.0 1.2 calico-node 963 root 4.7 3.5 kubelet 1121 root 1.3 2.1 dockerd 3057 root 0.7 0.8 speaker 9 root 0.3 0.0 rcu_sched 542 root 0.3 0.2 vmtoolsd 973 root 0.3 1.1 containerd 2214 root 0.3 1.0 kube-scheduler 49390 root 0.3 0.0 kworker/1:2
top性能统计信息
top性能统计信息
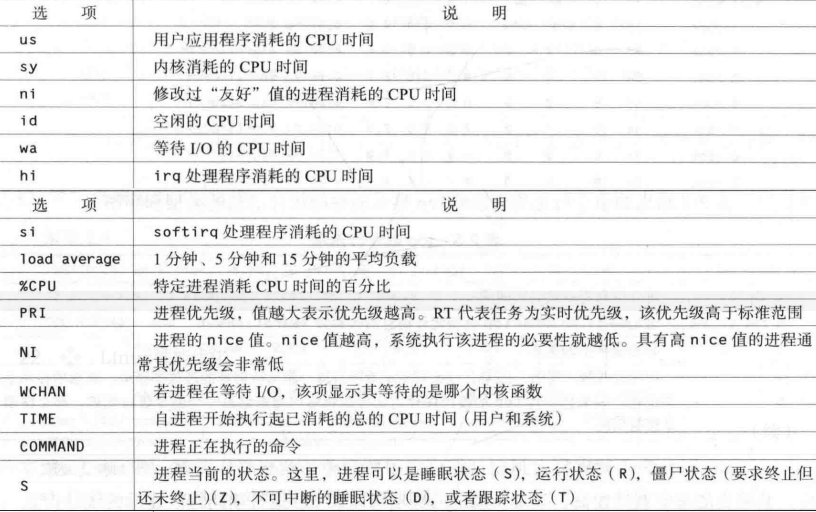
%Cpu(s): 5.3 us(用户消耗), 2.8 sy(系统消耗), 0.0 ni(友好值进程消耗), 91.9 id(空闲CPU), 0.0 wa(等待I/O的CPU时间), 0.0 hi(irp处理程序消耗的CPU时间), 0.0 si(softirq处理消耗), 0.0 st(这个不知道)
top - 09:26:22 up 13:08, 1 user, load average: 0.56, 0.48, 0.55(1分钟、5分钟和15分钟的平均负载)
列名 command为当前进程执行的命令,更多小伙伴可以结合命令列表理解
mpstat (多处理器统计) mpstat是一个相当简单的命令,向你展示随着时间变化的CPU行为。mpstat最大的优点是在统计信息的旁边显示时间,由此,你可以找出CPU使用率与时间的关系。
如果你有多个CPU或超线程CPU, mpstat还能够把CPU使用率按处理器进行区分,因此你可以发现与其他处理器相比,是否某个处理器做了更多的工作。你可以选择想要监控的单个处理器,也可以要求mpstat对所有的处理器都进行监控。
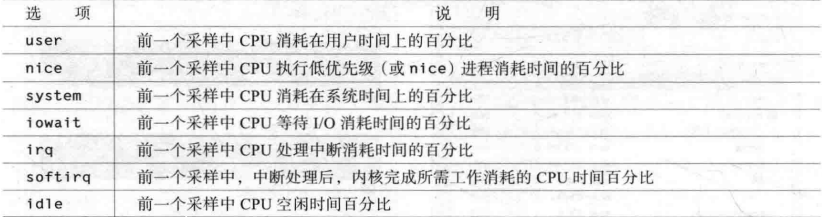
语法 1 2 3 4 5 6 7 8 ┌──[root@liruilongs.github.io]-[~] └─$ mpstat -help 用法: mpstat [ 选项 ] [ <时间间隔> [ <次数> ] ] 选项: [ -A ] [ -u ] [ -V ] [ -I { SUM | CPU | SCPU | ALL } ] [ -P { <cpu> [,...] | ON | ALL } ] ┌──[root@liruilongs.github.io]-[~] └─$
CPU性能相关的选项 1 mpstat -P { cpu | ALL} | delay [ count ]]
CPU性能相关的选项
使用-P监控0所在的CPU
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ┌──[root@liruilongs.github.io]-[~] └─$ mpstat -P 0 Linux 3.10.0-693.el7.x86_64 (liruilongs.github.io) 2022年01月15日 _x86_64_ (2 CPU) 11时31分09秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 11时31分09秒 0 0.53 0.00 0.53 0.06 0.00 0.06 0.00 0.00 0.00 98.82 ┌──[root@liruilongs.github.io]-[~] └─$ mpstat -P 1 Linux 3.10.0-693.el7.x86_64 (liruilongs.github.io) 2022年01月15日 _x86_64_ (2 CPU) 11时31分13秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 11时31分13秒 1 0.52 0.00 0.53 0.06 0.00 0.05 0.00 0.00 0.00 98.84 ┌──[root@liruilongs.github.io]-[~] └─$
监控所有的CPU
1 2 3 4 5 6 7 8 9 10 ┌──[root@liruilongs.github.io]-[~] └─$ mpstat -P ALL Linux 3.10.0-693.el7.x86_64 (liruilongs.github.io) 2022年01月15日 _x86_64_ (2 CPU) 11时35分17秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 11时35分17秒 all 0.53 0.00 0.53 0.06 0.00 0.06 0.00 0.00 0.00 98.83 11时35分17秒 0 0.53 0.00 0.53 0.06 0.00 0.06 0.00 0.00 0.00 98.82 11时35分17秒 1 0.52 0.00 0.52 0.06 0.00 0.05 0.00 0.00 0.00 98.84 ┌──[root@liruilongs.github.io]-[~] └─$
监控3次,间隔1秒
1 2 3 4 5 6 7 8 9 10 11 ┌──[root@liruilongs.github.io]-[~] └─$ mpstat -P 0 1 3 Linux 3.10.0-693.el7.x86_64 (liruilongs.github.io) 2022年01月15日 _x86_64_ (2 CPU) 11时33分15秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 11时33分16秒 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 11时33分17秒 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 11时33分18秒 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 平均时间: 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 ┌──[root@liruilongs.github.io]-[~] └─$
CPU统计信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ┌──[root@liruilongs.github.io]-[~] └─$ mpstat -P ALL 1 2 Linux 3.10.0-693.el7.x86_64 (liruilongs.github.io) 2022年01月15日 _x86_64_ (2 CPU) 11时37分52秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 11时37分53秒 all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 11时37分53秒 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 11时37分53秒 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 11时37分53秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 11时37分54秒 all 0.51 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.49 11时37分54秒 0 1.02 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 98.98 11时37分54秒 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 平均时间: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 平均时间: all 0.26 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.74 平均时间: 0 0.51 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.49 平均时间: 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 ┌──[root@liruilongs.github.io]-[~] └─$
sar (系统活动报告) sar是一种低开销的、记录系统执行情况信息的方法
sar命令可以用于记录性能信息,回放之前的记录信息,以及显示当前系统的实时信息。sar命令的输出可以进行格式化,使之易于导入数据库,或是输送给其他Linux命令进行处理。
如果没有命令,可以启动服务看看
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$ pwd /usr/lib/systemd/system ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$ cat sysstat.service [Unit] Description=Resets System Activity Logs [Service] Type=oneshot RemainAfterExit=yes User=root ExecStart=/usr/lib64/sa/sa1 --boot [Install] WantedBy=multi-user.target ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$ systemctl status sysstat.service ● sysstat.service - Resets System Activity Logs Loaded: loaded (/usr/lib/systemd/system/sysstat.service; enabled; vendor preset: enabled) Active: active (exited) since Wed 2021-10-13 01:53:41 CST; 1 weeks 3 days ago Main PID: 584 (code=exited, status=0/SUCCESS) CGroup: /system.slice/sysstat.service Oct 13 01:53:41 liruilongs.github.io systemd[1]: Starting Resets System Activity Logs... Oct 13 01:53:41 liruilongs.github.io systemd[1]: Started Resets System Activity Logs.
语法 命令帮助文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 ┌──[root@liruilongs.github.io]-[~] └─$ sar -h 用法: sar [ 选项 ] [ <时间间隔> [ <次数> ] ] 主选项和报告: -b I/O 和传输速率信息状况 -B 分页状况 -d 块设备状况 -F [ MOUNT ] Filesystems statistics -H 交换空间利用率 -I { <中断> | SUM | ALL | XALL } 中断信息状况 -m { <关键词> [,...] | ALL } 电源管理统计信息 关键字: CPU CPU 频率 FAN 风扇速度 \t\tFREQ\tCPU 平均时钟频率 IN 输入电压 TEMP 设备温度 \t\tUSB\t连接的USB 设备 -n { <关键词> [,...] | ALL } 网络统计信息 关键词可以是: DEV 网卡 EDEV 网卡 (错误) NFS NFS 客户端 NFSD NFS 服务器 SOCK Sockets (套接字) (v4) IP IP 流 (v4) EIP IP 流 (v4) (错误) ICMP ICMP 流 (v4) EICMP ICMP 流 (v4) (错误) TCP TCP 流 (v4) ETCP TCP 流 (v4) (错误) UDP UDP 流 (v4) SOCK6 Sockets (套接字) (v6) IP6 IP 流 (v6) EIP6 IP 流 (v6) (错误) ICMP6 ICMP 流 (v6) EICMP6 ICMP 流 (v6) (错误) UDP6 UDP 流 (v6) -q 队列长度和平均负载 -r 内存利用率 -R 内存状况 -S 交换空间利用率 -u [ ALL ] CPU 利用率 -v Kernel table 状况 -w 任务创建与系统转换统计信息 -W 交换信息 -y TTY 设备状况 ┌──[root@liruilongs.github.io]-[~] └─$
红帽8没有,需要自己开启,红帽7有,下面为历史监控的存放位置
1 2 3 4 5 ┌──[root@liruilongs.github.io]-[/] └─$ cd /var/log /sa ┌──[root@liruilongs.github.io]-[/var/log /sa] └─$ ls sa01 sa03 sa04 sa05 sa06 sa08 sa09 sa13 sa14 sa23 sa24 sa30 sar03
CPU性能相关的选项 1 $sar [options] [] delay [ count ]]
尽管sar的报告涉及Linux多个不同领域,其统计数据有两种不同的形式。一组统计数据是采样时的瞬时值。另一组则是自上一次采样后的变化值。
sar命令行选项
1 2 3 4 5 6 7 8 9 10 ┌──[root@liruilongs.github.io]-[~] └─$ sar Linux 3.10.0-693.el7.x86_64 (liruilongs.github.io) 2022年01月15日 _x86_64_ (2 CPU) 11时00分01秒 CPU %user %nice %system %iowait %steal %idle 11时10分01秒 all 0.12 0.00 0.12 0.00 0.00 99.76 11时20分01秒 all 0.11 0.00 0.11 0.00 0.00 99.78 11时30分01秒 all 0.13 0.00 0.13 0.00 0.00 99.73 11时40分01秒 all 0.11 0.00 0.11 0.00 0.00 99.78 平均时间: all 0.12 0.00 0.12 0.00 0.00 99.76
**使用 -o 选项输出到指定文件 **,
1 2 3 4 5 6 7 8 9 ┌──[root@liruilongs.github.io]-[~] └─$ sar -o /tmp/apache_tets 1 3 Linux 3.10.0-693.el7.x86_64 (liruilongs.github.io) 2022年01月15日 _x86_64_ (2 CPU) 18时02分24秒 CPU %user %nice %system %iowait %steal %idle 18时02分25秒 all 0.00 0.00 0.56 0.00 0.00 99.44 18时02分26秒 all 0.00 0.00 0.00 0.00 0.00 100.00 18时02分27秒 all 0.00 0.00 0.00 0.00 0.00 100.00 平均时间: all 0.00 0.00 0.18 0.00 0.00 99.82
通过 -f 来查看指定文件信息
1 2 3 4 5 6 7 8 9 10 11 ┌──[root@liruilongs.github.io]-[~] └─$ sar -f /tmp/apache_tets Linux 3.10.0-693.el7.x86_64 (liruilongs.github.io) 2022年01月15日 _x86_64_ (2 CPU) 18时02分24秒 CPU %user %nice %system %iowait %steal %idle 18时02分25秒 all 0.00 0.00 0.56 0.00 0.00 99.44 18时02分26秒 all 0.00 0.00 0.00 0.00 0.00 100.00 18时02分27秒 all 0.00 0.00 0.00 0.00 0.00 100.00 平均时间: all 0.00 0.00 0.18 0.00 0.00 99.82 ┌──[root@liruilongs.github.io]-[~] └─$
使用 -P指定CPU
1 2 3 4 5 6 7 8 9 ┌──[root@liruilongs.github.io]-[~] └─$ sar -P 0 | head -5 Linux 3.10.0-693.el7.x86_64 (liruilongs.github.io) 2022年01月15日 _x86_64_ (2 CPU) 11时00分01秒 CPU %user %nice %system %iowait %steal %idle 11时10分01秒 0 0.12 0.00 0.12 0.01 0.00 99.75 11时20分01秒 0 0.12 0.00 0.11 0.00 0.00 99.77 ┌──[root@liruilongs.github.io]-[~] └─$
-w 上下文切换次数
1 2 3 4 5 6 7 8 9 ┌──[root@liruilongs.github.io]-[~] └─$ sar -P 0 -w | head -5 Linux 3.10.0-693.el7.x86_64 (liruilongs.github.io) 2022年01月15日 _x86_64_ (2 CPU) 11时00分01秒 proc/s cswch/s 11时10分01秒 0.92 313.58 11时20分01秒 0.81 316.81 ┌──[root@liruilongs.github.io]-[~] └─$
-q 运行队列长度和平均负载
1 2 3 4 5 6 7 ┌──[root@liruilongs.github.io]-[~] └─$ sar -q | head -5 Linux 3.10.0-693.el7.x86_64 (liruilongs.github.io) 2022年01月15日 _x86_64_ (2 CPU) 11时00分01秒 runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15 blocked 11时10分01秒 0 219 0.01 0.08 0.53 0 11时20分01秒 0 219 0.03 0.03 0.29 0
sar CPU统计信息
procinfo (从/proc文件系统显示信息) procinfo也为系统整体信息特性提供总览,它提供的有些信息与vmstat相同,但它还会给出CPU从每个设备接收的中断数量
CPU性能相关的选项 1 $procinfo [-f] [-d] [-D] [-n sec] [-f file]
嗯,这个命令没找到,以后再研究下
gnome-system-monitor
嗯,用SSH连接的机器,这个也以后再研究下
oprofile oprofile是性能工具包,它利用几乎所有现代处理器都有的性能计数器来跟踪系统整体以及单个进程中CPU时间的消耗情况。除了测量CPU周期消耗在哪里之外, oprofile还可以测量关于CPU执行的非常底层的信息。
根据由底层处理器支持的事件,它可以测量的内容包括: cache缺失、分支预测错误和内存引用,以及浮点操作。profile不会记录发生的每个事件,相反,它与处理器性能硬件一起工作,每count个事件采样一次,这里的count是一个数值,由用户在启动oprofile时指定。count的值越·低,结果的准确度越高,而oprofile的开销越大。若count保持在一个合理的数值,那么,oprofile不仅运行开销非常低,并且还能以令人惊讶的准确性描述系统性能。
1 2 ┌──[root@liruilongs.github.io]-[~] └─$ yum -y install oprofile
CPU性能相关的选项 oprofile实际上是一组协同工作的组件,用于收集CPU性能统计信息。oprofile主要有三个部分:
oprofile核心模块控制处理器并允许和禁止采样,oprofile后台模块收集采样,并将它们保存到磁盘。oprofile报告工具获取收集的采样,并向用户展示它们与在系统上运行的应用程序的关系
oprofile工具包使用opcontrol命令中。opcontrol命令用于选择处理器采样的事件并启动采样。进行后台控制时,你可以使用如下命令行调用
1 $opcontrol [--start] [--stop] [--dump]
1 2 3 4 5 6 7 8 ┌──[root@liruilongs.github.io]-[~] └─$ opcontrol -s ATTENTION: Use of opcontrol is discouraged. Please see the man page for operf. No vmlinux file specified. You must specify the correct vmlinux file, e.g. opcontrol --vmlinux=/path/to/vmlinux If you do not have a vmlinux file, use opcontrol --no-vmlinux Enter opcontrol --help for full options
这个貌似有些复杂,先不看了,之后遇到有机会再学习
关于CPU的性能调优工具就学到这里,欢迎小伙伴指正
![《Linux性能优化_[美] 菲利普G.伊佐特》](https://img-blog.csdnimg.cn/cab20b15858d411784b20260cac58851.png)
![《Linux性能优化_[美] 菲利普G.伊佐特》](https://img-blog.csdnimg.cn/9ed5b50d459b46cfad57e32bc8eb417a.png)